
I am a Nanyang Associate Professor at the School of Computer Science and Engineering, Nanyang Technological University, Singapore. My research interests lie mainly in Computational Narrative Intelligence, Multi-modal Learning, and Machine Learning.
Prior to NTU, I was a Senior Research Scientist at Baidu Research USA, and a Research Scientist and Group Leader at Disney Research. I received my Ph.D. degree from Georgia Institute of Technology.
Story is a powerful tool for communication, an exhibit of creativity, and a timeless form of entertainment. Computational Narrative Intelligence (CNI) aims to create intelligent machines that can understand and create stories, manage interactive narratives, and respond appropriately to stories told to them. I have made contributions to all major areas of CNI, ranging from story generation and interactive narratives to human cognition, from learning story knowledge to story understanding.
CNI is obviously a hard problem, requiring semantic understanding and powerful learning algorithms. Therefore, I am also interested in methods that learn grounded, multimodal semantics and strong machine learning algorithms. In particular, I am excited by techniques that adopt a system view of intelligence, which considers the interaction of multiple specialized components.
gs.ude.utn@il.gnayob :liamE
Selected Papers
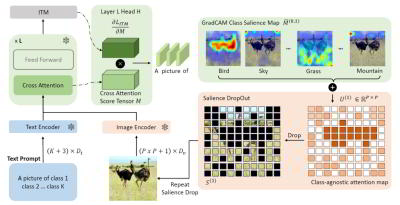
Luo Jiayun, Siddhesh Khandelwal, Leonid Sigal, and Boyang Li. Emergent Open-Vocabulary Semantic Segmentation from Off-the-shelf Vision-Language Models. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2024.
TL;DR: We extract semantic segmentation for arbitrary classes directly from pretrained vision-language models (BLIP and BridgeTower) without any additional training.
Paper bibtex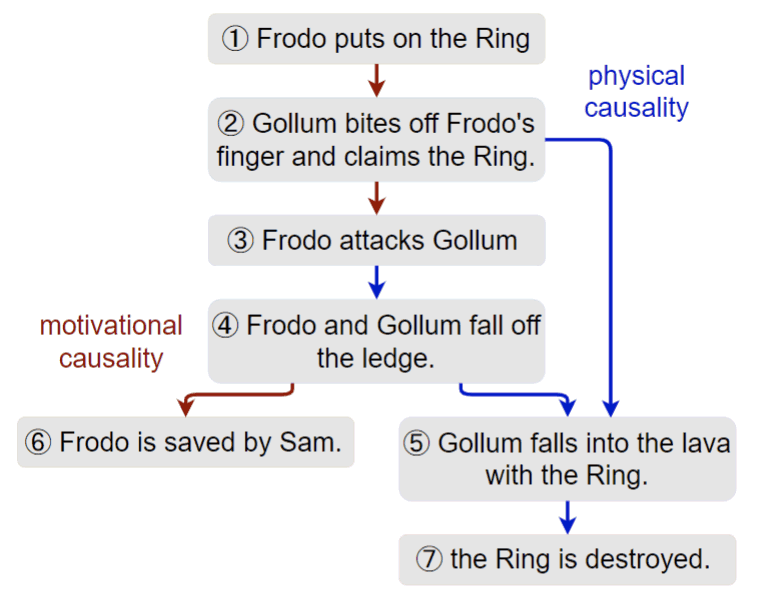
Yidan Sun, Qin Chao, and Boyang Li. Event Causality Is Key to Computational Story Understanding. The 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). 2024.
TL;DR: We demonstrate the value of LLM-extracted causal relations between events in story understanding tasks.
Paper Code bibtex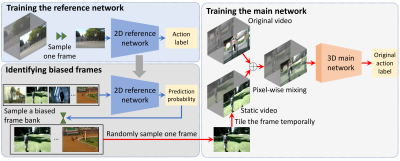
Haoxin Li, Yuan Liu, Hanwang Zhang, and Boyang Li. Mitigating and Evaluating Static Bias of Action Representations in the Background and the Foreground. International Conference on Computer Vision (ICCV) (Oral Presentation). 2023.
TL;DR: Video classifiers often rely on static features to make biased predictions. We show that static bias is caused by not only the background, but also the foreground, such as human actor's outfit or instrument. We propose a theory-inspired method to mitigate bias without having to locate the source.
Paper Supplemental Code bibtex
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. NeurIPS. 2023.
TL;DR: An instruction-tuned vision-language model that achieves state-of-the-art performance on several benchmarks.
Paper Code Model Zoo bibtex
Yidan Sun, Qin Chao, Yangfeng Ji, and Boyang Li. Synopses of Movie Narratives: a Video-Language Dataset for Story Understanding. ArXiv Preprint 2203.05711. 2022.
TL;DR: A large, plot-level, multimodal dataset for story understanding. The storytelling techniques of the paper create unique challenges for the current generation of multimodal networks.
Paper Data bibtex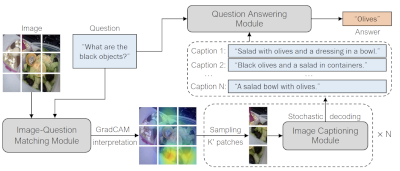
Anthony Meng Huat Tiong, Junnan Li, Boyang Li, Silvio Savarese, and Steven C.H. Hoi. Plug-and-Play VQA: Zero-shot VQA by Conjoining Large Pretrained Models with Zero Training. Findings of the Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP). 2022.
TL;DR: An unexpected modular approach to visual question answering. We translate relevant portions of an image to text and rely on text-based reasoning entirely. On VQAv2, the results are better than Deepmind's Flamingo by 8.5%. This is in contrast to conventional wisdom that end-to-end learning is necessary for good performance.
Paper Video Code bibtex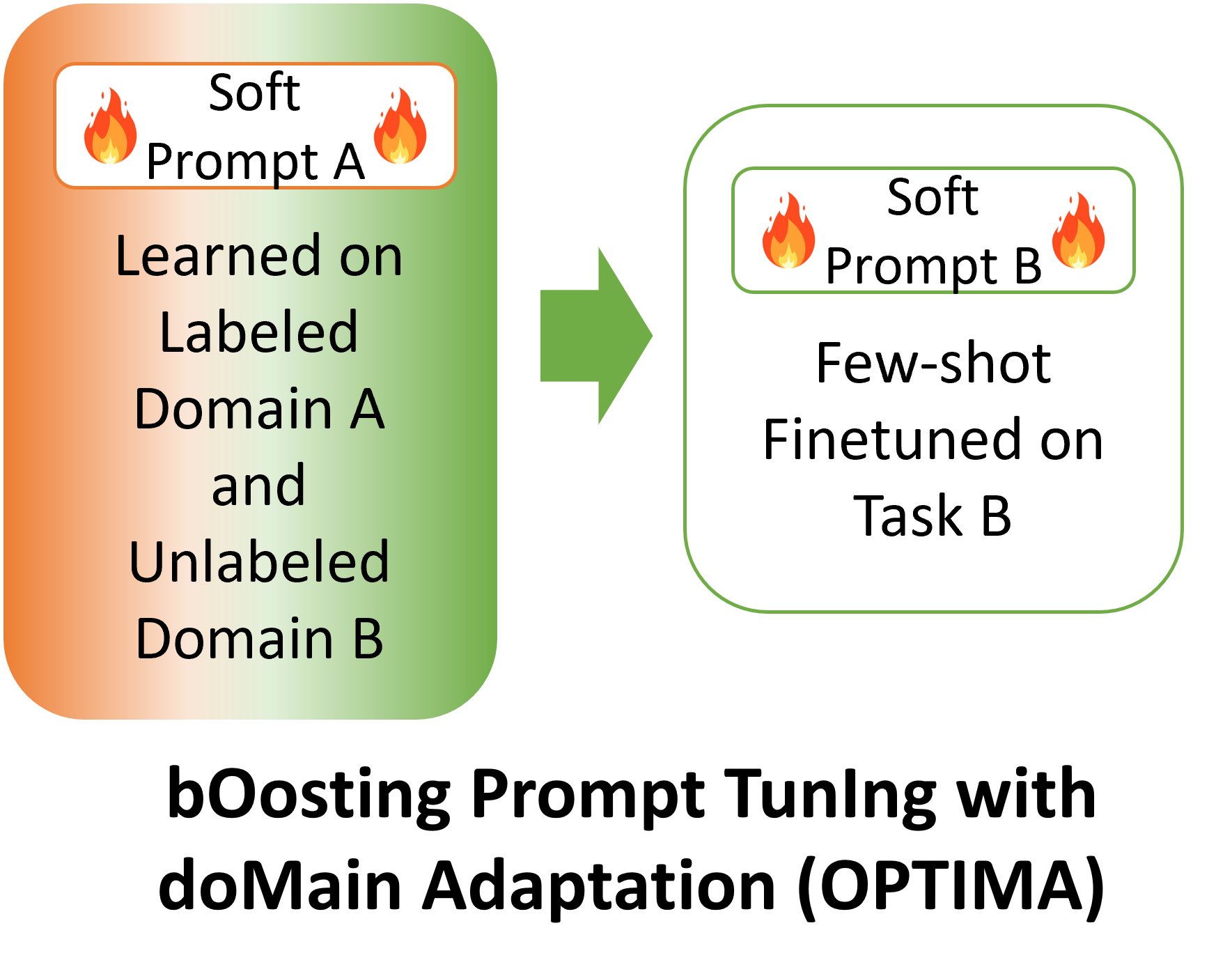
Xu Guo, Boyang Li, and Han Yu. Improving the Sample Efficiency of Prompt Tuning with Domain Adaptation. Findings of the Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP). 2022.
TL;DR: Prompt tuning is great for large model deployment but requires a lot of training data. To our knowledge, we are the first in using unlabeled data in the target domain to improve prompt tuning.
Paper Code bibtex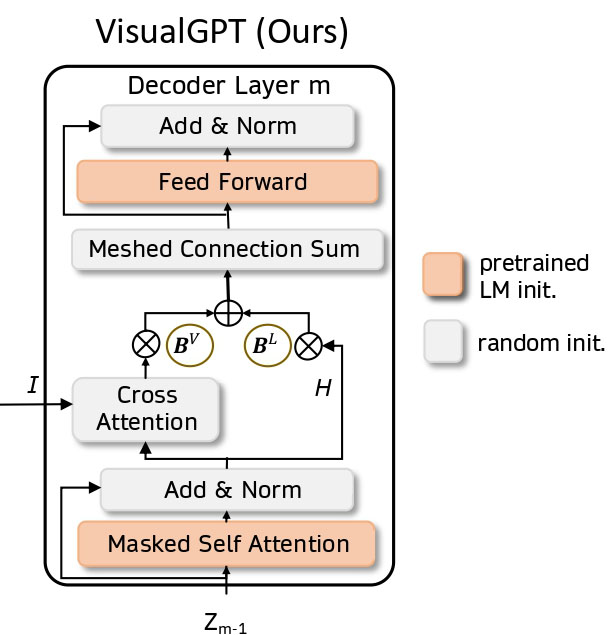
Jun Chen, Han Guo, Kai Yi, Boyang Li, and Mohamed Elhoseiny. VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.
TL;DR: We developed a data-efficient method to adapt large-scale pretrained language models for image captioning and achieved SOTA results on X-ray image captioning.
Paper Code bibtex
Yinan Zhang, Boyang Li, Yong Liu, Hao Wang, Chunyan Miao. Initialization Matters: Regularizing Manifold-informed Initialization for Neural Recommendation Systems. ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2021.
TL;DR: If neural recommenders performed poorly (e.g., worse than well-tuned k-nearest-neighbors), it is probably because they did not use this data-dependent, manifold-informed initialization.
Paper Video Code bibtexXu Guo, Boyang Li, Han Yu, and Chunyan Miao. Latent-Optimized Adversarial Neural Transfer for Sarcasm Detection. The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT). 2021.
TL;DR: Sarcasm detection is an ideal problem for transfer learning. We identify the competition between losses in adversarial transfer learning and propose a modified optimization technique to solve the problem, which achieves the SOTA result on the iSarcasm dataset.
Paper Code bibtex
Chang Liu, Han Yu, Boyang Li, Zhiqi Shen, Zhanning Gao, Peiran Ren, Xuansong Xie, Lizhen Cui, and Chunyan Miao. Noise-resistant Deep Metric Learning with Ranking-based Instance Selection. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021.
TL;DR: We introduce a simple, efficient, and (we believe) the first technique for deep metric learning under noisy training data; the method outperforms 12 baseline methods under both synthetic and natural noise.
Paper Supplemental Video 视频 Code bibtex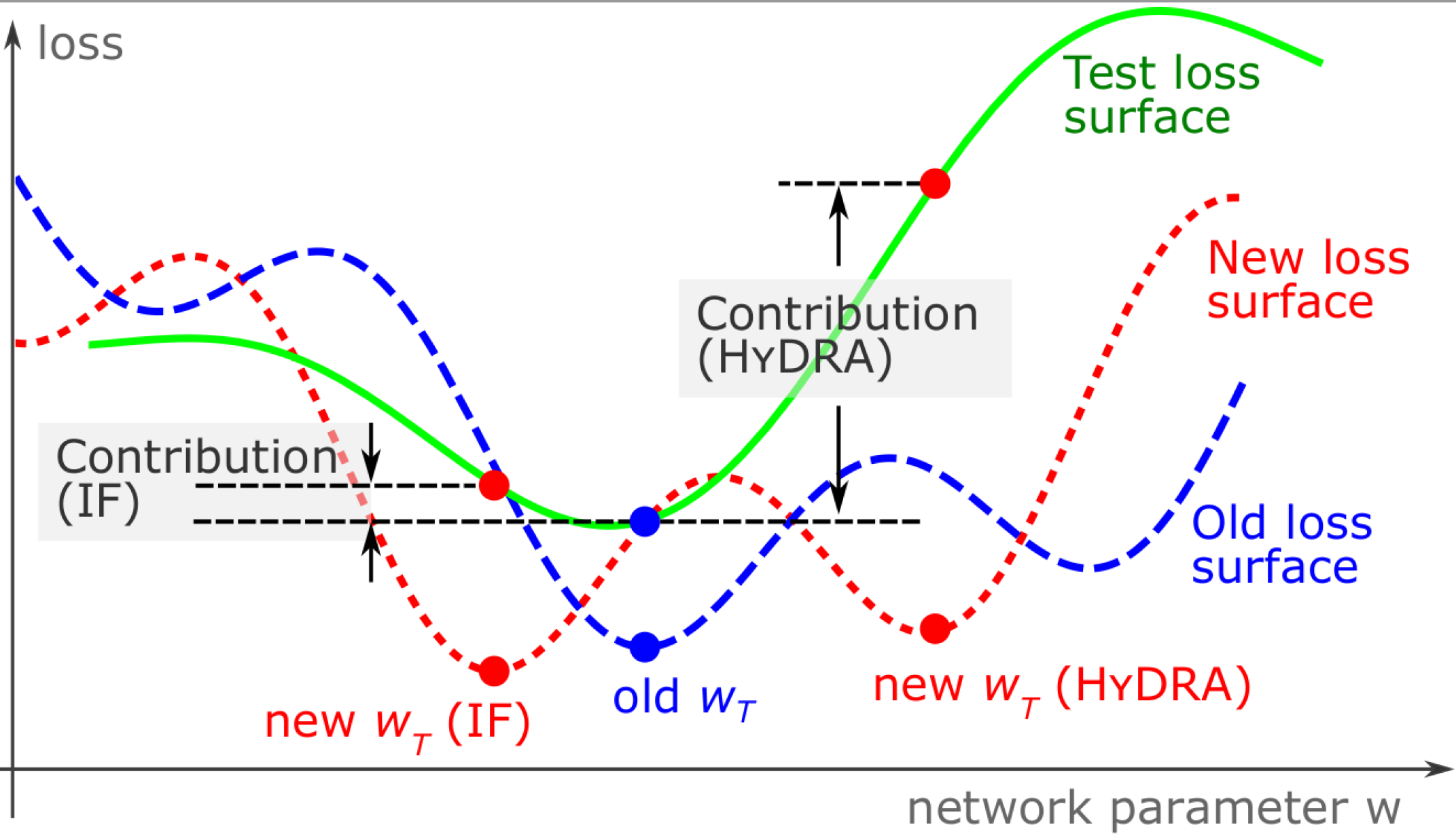
Yuanyuan Chen, Boyang Li, Han Yu, Pengcheng Wu, and Chunyan Miao. HyDRA: Hypergradient Data Relevance Analysis for Interpreting Deep Neural Networks. The AAAI Conference on Artificial Intelligence (AAAI). 2021.
TL;DR: We provide an approximate hypergradient method for estimating how training data contribute to individual network predictions and a theoretical bound on the approximation error.
Paper Supplemental Code bibtex
Adam Noack, Isaac Ahern, Dejing Dou, and Boyang Li. An Empirical Study on the Relation between Network Interpretability and Adversarial Robustness Springer Nature Computer Science. 2020.
TL;DR: Does the interpretability of neural networks imply robustness against adversarial attack? We provide some positive empirical evidence.
Paper Code bibtex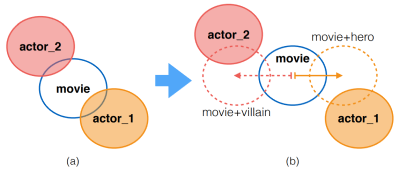
Hannah Kim, Denys Katerenchuk, Daniel Billet, Jun Huan, Haesun Park, and Boyang Li. Understanding Actors and Evaluating Personae with Gaussian Embeddings. The AAAI Conference on Artificial Intelligence (AAAI). 2019.
TL;DR: We computationally model movie casting decisions and actors' versatility.
Paper Code & Data bibtex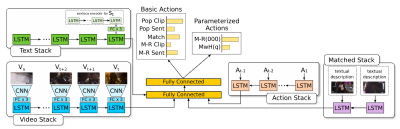
Pelin Dogan, Boyang Li, Leonid Sigal, Markus Gross. A Neural Multi-sequence Alignment TeCHnique (NeuMATCH). The Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
TL;DR: We propose the first end-to-end optimizable network for aligning video and text sequences.
Paper Data bibtex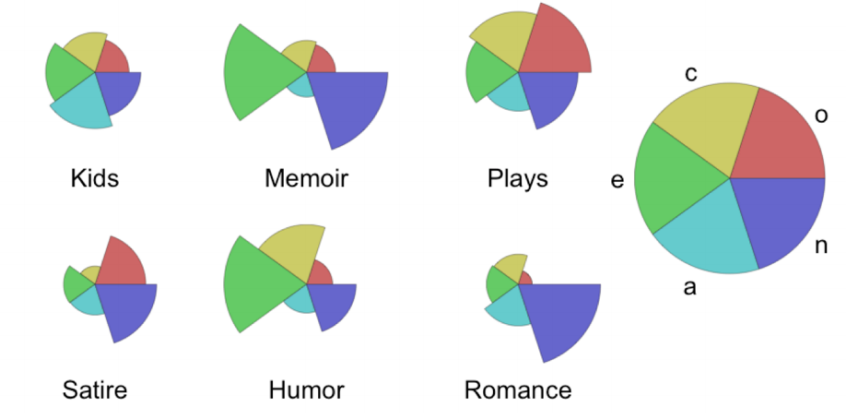
Ng Annalyn, Maarten Bos, Leonid Sigal, Boyang Li. Predicting Personality from Book Preferences with User-Generated Content Labels. IEEE Transaction on Affective Computing. 2018.
TL;DR: We can infer your personality from the books you read.
Paper bibtexHiring
I have multiple open positions for Ph.D. students, postdocs, and research engineers. Please send me your CV.
What's New
- Mar 2024: 2 papers accepted to NAACL 2024.
- Jan/Feb 2024: 1 AAAI paper and 2 CVPR papers accepted.
- Dec 2023: I presented recent work as an invited speaker at the Workshop on Effective Multimodal Perception and Interactive Learning, at the 6th Asia Conference on Cognitive Engineering and Intelligent Interaction.
- Nov 2023: I presented recent work as an invited speaker at the Workshop on Large Generative Models Meet Multimodal Applications, ACM Multimedia.
- Aug 2023: 1 paper accepted at ACM Computing Surveys.
- Jul 2023: 1 paper accepted at ICCV (Oral) and 1 paper accepted at ACM MM.
- Jun 2023: Presented recent work at the University of British Columbia, Canada. [Slides]
- Jun 2023: Attended CVPR in Vancover, Canada.
- Apr 2023: Visiting University of Malaya at Kuala Lumpur, Malaysia.
- Mar 2023: One paper on Visual Question Answering accepted to CVPR 2023. One paper accepted to ICME 2023.
- Feb 2023: I presented recent work at Tsinghua University and Shandong University.
- Jan 2023: I served as a Senior Action Editor for ACL Rolling Review.
- Dec 2022: I was at EMNLP 2022 in Abu Dhabi, UAE.
- Oct 2022: Three papers accepted to EMNLP Findings 2022.
- July-Nov 2022: I served as an Area Chair (Senior Meta-reviewer) for AAAI 2022, overseeing 40+ papers.
- May 2022: At ACL 2022.
- May 2022: Gave a talk about recent work on machine learning at Microsoft Research Cambridge.
- Mar 2022: Multiple paper acceptance. One to CVPR 2021, one to the ACM Transactions on Intelligent Systems and Technology, and one to the 4th workshop on NLP for ConvAI.
- Sep 2021: Presented recent work to world-renowned scientists at the WLF Young Scientist Forum. [Slides]
- Sep 2021: Reviewing papers for WACV 2022 and AAAI 2022.
- Jun-Oct 2021: Serving as an area chair for Narrative Systems at ICIDS 2021, a leading conference for AI and narratives. Mar 2021: Received the NRF Fellowship award with funding of 3M SGD.